Art creation with Python, Machine Learning and Language Processing
During the time that I spent on the weekend reading about new things and stuff that I consider awesome, I dive into an interesting and emerging field of AI which is Images and Art Creation.
To be more specific, I started to work with models that create images, pixel art, and art, and I found it incredible.
Some work performed here is related to upcoming academic works, so this is half for fun and half academic related stuff.
I discovered algorithms and software that is fascinating, so I wanted to make a brief entry in my blog about them.
DALL·E: Creating Images from Text
DALL·E is a 12-billion parameter version of GPT-3, created by OpenAI, trained to generate images from text descriptions, using a dataset of text–image pairs. We’ve found that it has a diverse set of capabilities, including creating anthropomorphized versions of animals and objects, combining unrelated concepts in plausible ways, rendering text, and applying transformations to existing images.
All this is pretty impressive, let’s see a little bit more about DALL-E. In the next pictures you can check images automatically generated with DALL-E :
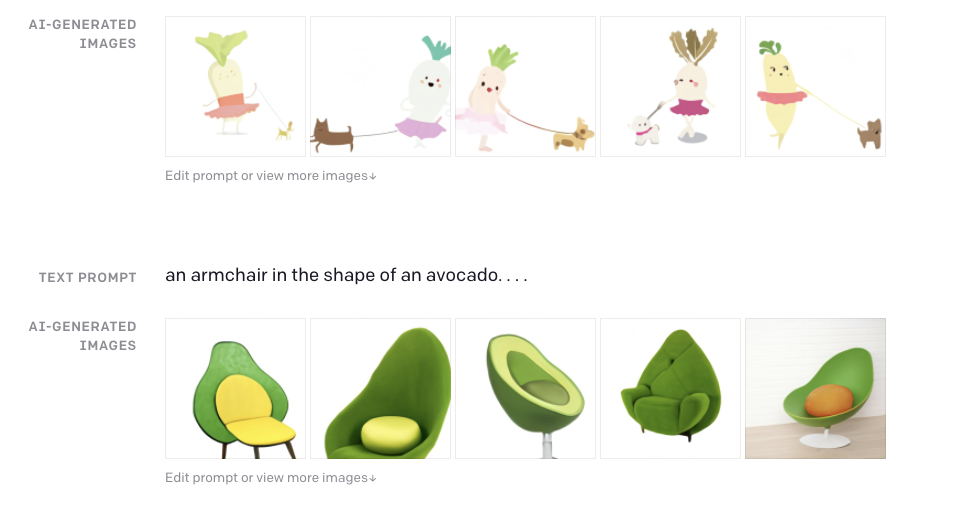
As we can see, entering some descriptive text the software will generate images. But, not easy images or easy flows like “draw a cat” and the resulting animal, in this case the Model supports really advanced features like being able to draw an armchair in the shape of an avocado.
DALL·E is a transformer language model. It receives both the text and the image as a single stream of data containing up to 1280 tokens, and is trained using maximum likelihood to generate all of the tokens, one after another. This training procedure allows DALL·E to not only generate an image from scratch, but also to regenerate any rectangular region of an existing image that extends to the bottom-right corner, in a way that is consistent with the text prompt.
As the creators says, the work involving generative models has the potential for significant, broad societal impacts. Even, they expect to analyze how models like DALL·E relate to societal issues like economic impact on certain work processes and professions, the potential for bias in the model outputs, and the longer term ethical challenges implied by this technology.
DALL·E is able to create plausible images for a great variety of sentences that explore the compositional structure of language.
Support for multiple objects
DALL-E Model is able to work with multiple objects. Controlling multiple objects, their attributes, and their spatial relationships presents a challenge. For example, consider the phrase “a hedgehog wearing a red hat, yellow gloves, blue shirt, and green pants.” To correctly interpret this sentence, DALL·E must not only correctly compose each piece of apparel with the animal, but also form the associations (hat, red), (gloves, yellow), (shirt, blue), and (pants, green) without mixing them up. We test DALL·E’s ability to do this for relative positioning, stacking objects, and controlling multiple attributes.
Let’s see some of the proposed examples

Combining Unrelated Concepts
The compositional nature of language allows us to put together concepts to describe both real and imaginary things. We find that DALL·E also has the ability to combine disparate ideas to synthesize objects, some of which are unlikely to exist in the real world. We explore this ability in two instances: transferring qualities from various concepts to animals, and designing products by taking inspiration from unrelated concepts.

DALL-E supports many advanced features like that we are going to analyze in the part 2 of this article like; Visualizing Perspective and Three-Dimensionality, Visualizing Internal and External Structure, Inferring Contextual Details.
The model of DALL-E was released in a similar a piece of software called CLIP or Contrastive Image-Language Pretraining. Clip is able to evaluate and qualify images, seeing if the image matches properly a given a text.
The approach used actually is to combine both to create a software qualified enough to score a given image created by Wall-e or another piece of software like VQGAN (Vector Quantized GAN) that will be qualified by CLIP.
Some of this kind of software is not released for the big public, alternatives like clip or vqgan let us try and use this kind technology openly, even when some pieces of OpenAI are not disclosed yet, or are released partially or for some group of people. An interesting approach, that I love, is that almost everything in the AI field is fully or partially released under friendly licenses that everyone can use. More on this later.
Combining an imagen generator with CLIP
All kind of things we can creeate and explore with this technologies. We can use complex pieces of text as input, and even we can use audio as input or output in this fascinating world of AI. In a next article Im going to explore the creation of bach like or baroque music with Python and Machine Learning. Let’s get back to art generation.
Pixray and Google Collab
You might be thinking that all this wonderful state of the art technology is amazing but difficult to use because it needs strong GPU power and expensive hardware.
This is real, but now with the amazing power of Google Collab, you can use a GPU as a Service ( a joke ) but it is what it is. Google Collab gives the power of GPU on the cloud, and you can use it free for an interesting amount of required resources.
So, it is possible to explore all this from a laptop or any kind of actual machine, which is amazing.
Pixray
You can use this repo of Collab engine, that is now used to host Google Colab notebooks which demostrate various pixray capabilities.
To illustrate how easy is to start using this engine, as it is explained here https://towardsdatascience.com/how-i-built-an-ai-text-to-art-generator-a0c0f6d6f59f
Using python and a few lines of code, in this case with the previous clipit now migrated under the name of pixray, you can start the flow to start iterations to create from language processing and incredible piece of art like the one we show in the last part of the article. This is just the beginning, we are going to explore deeply more things in the second part of this article that is coming next week.
1**import sys
2sys.path.append("clipit")
3import clipit
4
5# To reset settings to default
6clipit.reset_settings()
7
8# You can use "|" to separate multiple prompts
9prompts = "underwater city"
10
11# You can trade off speed for quality: draft, normal, better, best
12quality = "normal"
13
14# Aspect ratio: widescreen, square
15aspect = "widescreen"
16
17# Add settings
18clipit.add_settings(prompts=prompts, quality=quality, aspect=aspect)
19
20# Apply these settings and run
21settings = clipit.apply_settings()
22clipit.do_init(settings)
23cliptit.do_run(settings)**
Resultating images created synthetically with Python and the technologies I explained here.


Bibliography and resources
https://openai.com/blog/dall-e
https://github.com/dribnet/pixray
https://compvis.github.io/taming-transformers/
https://towardsdatascience.com/how-i-built-an-ai-text-to-art-generator-a0c0f6d6f59f
https://ljvmiranda921.github.io/notebook/2021/08/08/clip-vqgan/